Spring webflux入门实战
响应式编程概念
命令式编程
- 命令式编程详细的命令机器怎么去处理一件事情以达到你想要的结果。
- 命令式编程是一种阻塞模式的编程,也就是代码是按照所编写的顺序一行一行的执行。
响应式编程
- 响应式编程是一种数据流编程模式,程序所关注的是数据流而非控制流。
- 响应式编程则是一种非阻塞的异步编程,我们无需等待。
响应式编程的两个原则
异步原则
第一个异步原则。我们知道一个异步执行的任务可以让我们无须等待前一个任务执行完成,从而可以大大提高任务执行的效率及硬件的利用率,更为重要的是异步执行可让我们将任务进行解耦。
因此,Reactive Streams提供异步执行也正是基于这个原因。所以,当我们在编写响应式程序时一定要注意,一个发布者(Publisher)在生成所要发布的数据消息时,或者一个订阅者(Subscriber)在处理一个数据消息时可以是同步的、阻塞式的。但是,当发布者(Publisher)将数据发布给订阅者(Subscriber)时必须是异步的,它们之间不能产生阻塞,否则我们所讨论响应式编程将变成一个笑话。
背压机制(backpressure)
背压机制是响应式编程中一个非常重要的原则,也是我们在编写响应式程序时所必须遵守的一个原则。背压机制避免了订阅者(Subscriber)在处理事件时所面临的超限(overrun)状况。根据背压机制,发布者(Publisher)只能向订阅者(Subscriber)发布等于或少于订阅者所请求个数的数据消息,而订阅者可以视其自身处理能力来决定是否再向发布者请求更多数据消息。
而当发布者生产数据消息的速率大于订阅者处理速率的话,发布者可以构建缓存来存储尚未发送的事件,也可以简单的抛弃。具体采用何种策略则由具体业务来决定。
此外,对于订阅者来说视其应用场景的不同可以一次请求多个数据消息,也可以一次仅请求一个数据消息。
以下概念借鉴与知乎答案
什么是背压机制?Backpressure这个概念源自工程。原意是指在管道运输中,气流或液流由于管道突然变细、遇到急弯等原因导致出现了下游向上游的逆向压力,这种情况就称作back pressure,国内工程界这个词的翻译就是背压。
而在编程中是指数据流从上游生产者向下游消费者传输,上游生产速度大于下游消费速度,从而导致下游的Buffer溢出,我们就称这种现象为backpressure出现。
对于背压这个概念的理解需要强调一点是,背压的重点不在于上游生产速度大于下游消费速度,而在于下游Buffer溢出。因为一旦我们下游处理设置了Buffer,那么就有可能会遇到这种情况。但是,根据墨菲法则,下游一旦设置Buffer,则这种现象一定会发生。而且这种现象一旦出现,下游就面临一种危险的境地,此时下游唯一的选择就是丢弃上游发送过来的事件,别无它法。
异步非阻塞的理解
略。。。。
Reactive Streams
Java在JDK9之后引入了响应式编程范型:Reactive Streams。Reactive Streams提供了一套非阻塞具有背压的异步流处理标准。主要应用在JVM、JavaScript及网络协议的处理中。我们也可以这么理解: Reactive Streams定义了一套响应式编程的标准。
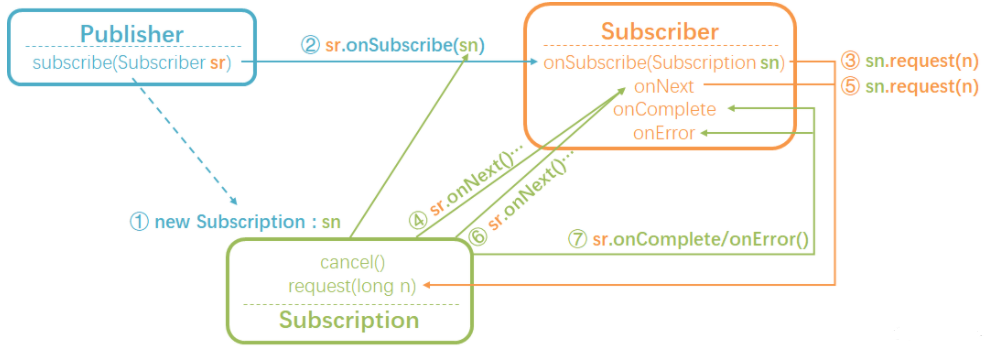
Reactive Streams定义了下面4个API接口:
Publisher
: 即事件或数据的发生源,它只有一个订阅方法: subscribe(),- subscribe() 调用该方法,建立订阅者Subscriber与发布者Publisher之间的消息订阅关系。
Subscriber
: 事件或数据的订阅者,也可以称为事件或数据的消费者。该接口提供了4个方法,分别用于处理 Publisher所发出的不同消息;- onSubscribe() 一旦订阅者成功注册到
Publisher,Publisher就会向订阅者发布一个订阅事件(subscription Event)事件,并将所构造Subscription对象传递给订阅者。后续订阅者可以使用该对象向Publisher发起数据消息请求等处理; - onNext()
Publisher发送给订阅者的所有数据事件消息均由该方法进行处理。不过需要强调一点,Publisher有可能一个数据事件都不会发布; - onError() 不论是在数据事件消息发布时,还是在订阅者订阅时,一旦出现异常
Publisher就会发布该事件给订阅者,订阅者可以在该方法中监听并进行相关处理。和完成事件一样,一旦Publisher向Subscriber发布了该事件消息,订阅者将不能够再向Publisher请求更多数据,而且Publisher也不能再发送任何事件给订阅者。此时,我们需要将订阅者所持有的Subsciption设置为无效,以防止再次数据请求。 - onComplete() 当
Publisher完成全部数据事件的发送时就会向订阅者发布该事件。一旦该事件发布,那么Subscriber就不能够再向Publisher请求任何数据,而且Publisher也不会再发送任何事件给订阅者。此时,我们需要将订阅者所持有的Subscription对象设置为空。不过,这里也需要强调一下,该事件有可能永远都不发布,比如Publisher出现异常时(此时发布的是异常事件)或者Publisher是一个无限数据消息发送者时,此事件也不会发布;
- onSubscribe() 一旦订阅者成功注册到
Subscription: 该接口用来描述每个订阅消息,有点类似我们在进行Web编程时所使用的会话信息(session),只不过该接口用来处理订阅者和发布者之间的关联信息。该接口有2个方法:
request()和cancel()。- request()方法则是向上游消息发布者(Publisher)索要指定个数的消息,也就是创建数据;
- cancel()则是告诉消息发布者取消消息的推送。注意,一旦我们调用了该方法,则Subscriber之后不再接受任何Publisher所发布的消息;
Processor<T, R>: 该接口同时继承了Publisher和Subscriber这两个接口。它即是一个消息发生者,也是一个消息的订阅者,一般可用对所要发布的消息进行转换、合并等处理,可以理解为是发生者和订阅者之间的一个处理管道。
需要着重说明的一点是:虽然Reactive Streams是Java所提出的一个响应式编程的标准,但是并在JDK中提供任何具体的实现,具体的实现则是由第三方提供,如:RxJava、Reactor、akka... 。后面讲一个以Reactor为实现的demo
响应式组件架构
响应式编程的优缺点
优点
- 避免"callback hell"(callback hell是指在js中所有异步都需要靠回调实现,当异步过多时造成代码嵌套大量回调 http://callbackhell.com)
- 大幅简化异步和线程操作
- 简单的组合数据流操作
- 复杂的线程操作变得简单
- 代码变得更清晰可读
- 轻松地实现“回压”
缺点
- 大多数情况下,需要更多的内存来存储数据流(因为它是基于时间流的)。
- 刚开始学习时可能会觉得不合常规(需要一切都顺畅)。
- 宣布新服务时必须处理大多数复杂性。
- 缺乏好的和简单的学习资源。
进入Reactor
正如之前所讲的,Java中所提供的Reactive Stream所仅仅是一个标准,其本身仅是相应的接口定义,并未提供任何具体的实现,而这些实现由第三方来完成。其中Reactor则是由Pivotal开源组织提供,该组织也是Spring的提供者,因此顺理成章Spring 5中所引入的响应式编程就是基于该项目完成。所以后续我们将会介绍Reactor,至于其它的实现,大家可以自行研究。
最新版本的Reactor,也就是3.x版,可以说是完全支持Reactive Streams所定义的标准,包括背压机制。在正式开始讲解Reactor 之前先让我们粗略了解一下Reactor的特性。
Reactor的特性
无限数据流
在数据流的发布上Reactor提供了无限数据流的支持。同时,针对背压机制,提供了request-respone模式,使得Reactor提供每次仅发送一个数据事件消息的能力。
推-拉模式的支持(push-pull model)
因为发布者和订阅者之间生产和消费速率的不同,所以Reactor在事件消息的处理上提供了推(push)和拉(pull)这两种模式。当发布者生产数据消息的速率大于订阅者消费速率的话,可以采用拉(pull)模式,由订阅者主动来拉取数据消息。而当发布者生产数据消息的速率小于订阅者消费速率的话,可采用发布者主动推送(push)的模式。
丰富的操作处理
Reactor提供了丰富的操作,使用这些操作我们可以对数据流进行筛选、过滤、转换以及合并等处理。Reacive Streams在对数据流处理上借鉴了Unix中管道处理模式,每一个操作都可视为管道中的一个节点,我们可以通过组合这些操作来构建各种处理,从而能够实现极为复杂的业务功能。
Reactor主要工程
- Reactor-Core: Reactor的核心工程,实现了Reactive Streams所定义的API,也是Spring 5中响应式编程的核心工程;
- Reactor-Extra: Reactor的扩展库,包含reactor-adapter和reactor-extra,增强了Reactor Core的功能;
- Reactor-Netty: 基于Netty,提供了非阻塞的、支持背压的TCP/HTTP/UDP客户端和服务端;
- Reactor-Test: Reactor的测试套件。
demo实现
定义一个Publisher
xxxxxxxxxx181public class HelloWorldPublisher implements Publisher<List<String>> {2
3 private final List<String> source;4
5 private HelloWorldPublisher(List<String> array) {6 this.source = array;7 }8
9 public static HelloWorldPublisher create(List<String> array) {10 return new HelloWorldPublisher(array);11 }12
13 14 public void subscribe(Subscriber<? super List<String>> subscriber) {15 TestSubscription testSubscription = new TestSubscription(source, subscriber);16 subscriber.onSubscribe(testSubscription);17 }18}定义一个Subscription
xxxxxxxxxx391 static class TestSubscription implements Subscription {2
3 private boolean cancelled = false;4 private long index = 0;5 private final int size;6 private final List<String> source;7 private final Subscriber<? super List<String>> subscriber;8
9 TestSubscription(List<String> source, Subscriber<? super List<String>> subscriber) {10 this.size = source.size();11 this.source = source;12 this.subscriber = subscriber;13 }14
15 16 public void request(long n) {17 if (n <= 0 || cancelled) {18 return;19 }20
21 if (index == size) {22 subscriber.onComplete();23 return;24 }25 try {26 List<String> list = source.stream().skip(index).limit(n).collect(Collectors.toList());27 index = index + n;28 subscriber.onNext(list);29 } catch (Exception e) {30 subscriber.onError(e);31 }32 }33
34 35 public void cancel() {36 System.out.println("===========cancel===========");37 cancelled = true;38 }39 }定义一个Subscriber
xxxxxxxxxx311public class HelloWorldSubscriber<T> implements Subscriber<T> {2
3 private Subscription subscription;4
5 6 public void onSubscribe(Subscription subscription) {7 System.out.println(subscription.getClass());8 this.subscription = subscription;9 //初始获取3个数据10 subscription.request(3);11 }12
13 14 public void onNext(T t) {15 System.out.println(t.toString());16 //消费出错直接抛异常17// throw new RuntimeException();18 //拒绝消费后面的数据,调用cancel方法使消费者停止生产数据19// subscription.cancel();20 subscription.request(1);21 }22
23 24 public void onError(Throwable t) {25 System.out.println("error");26 }27
28 29 public void onComplete() {30 System.out.println("complete");31 }测试
xxxxxxxxxx91public class HelloWorldReactor {2
3 public static void main(String[] args) {4 HelloWorldPublisher publisher = HelloWorldPublisher.create(Arrays.asList("abc","1234","hell","world","def"));5 HelloWorldSubscriber<List<String>> subscriber = new HelloWorldSubscriber<>();6 publisher.subscribe(subscriber);7 }8
9}
Flux与Mono
Flux
Flux 是生产者,即我们上面提到的 Publisher,它代表的是一个包含 0-N 个元素的异步序列。
我们看一个Flux是怎么transfer items的:
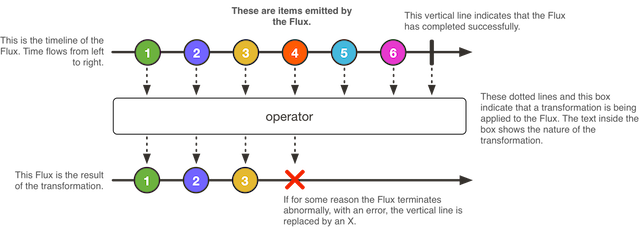
先看下Flux的定义:
xxxxxxxxxx11public abstract class Flux<T> implements Publisher<T> 可以看到Flux其实就是一个Publisher,用来产生异步序列。
Flux提供了非常多的有用的方法,来处理这些序列,并且提供了completion和error的信号通知。
相应的会去调用Subscriber的onNext, onComplete, 和 onError 方法。
Mono
Mono可以看做 Flux 的有一个特例,代表 0-1 个元素,如果不需要生产任何元素,只是需要一个完成任务的信号,可以使用 Mono。
我们看下Mono是怎么transfer items的:
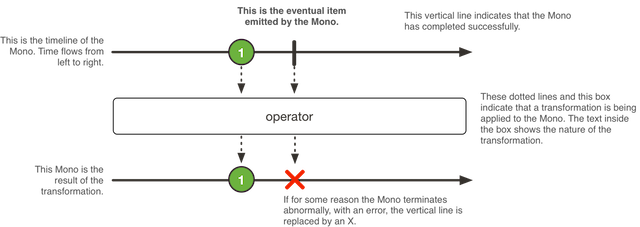
看下Mono的定义:
xxxxxxxxxx11public abstract class Mono<T> implements Publisher<T> Mono和Flux一样,也是一个Publisher,用来产生异步序列。
Mono因为只有0或者1个序列,所以只会触发Subscriber的onComplete和onError方法,没有onNext。
另一方面,Mono其实可以看做Flux的子集,只包含Flux的部分功能。
Mono和Flux是可以互相转换的,比如Mono#concatWith(Publisher)返回一个Flux,而 Mono#then(Mono)返回一个Mono.
Flux和Mono的基本操作
以Flux为例,我们看下Flux创建的例子:
xxxxxxxxxx41Flux<String> seq1 = Flux.just("foo", "bar", "foobar");2List<String> iterable = Arrays.asList("foo", "bar", "foobar");3Flux<String> seq2 = Flux.fromIterable(iterable);4Flux<Integer> numbersFromFiveToSeven = Flux.range(5, 3);可以看到Flux提供了很多种创建的方式,我们可以自由选择。
再看看Flux的subscribe方法:
xxxxxxxxxx151Disposable subscribe(); 2
3Disposable subscribe(Consumer<? super T> consumer); 4
5Disposable subscribe(Consumer<? super T> consumer,6 Consumer<? super Throwable> errorConsumer); 7
8Disposable subscribe(Consumer<? super T> consumer,9 Consumer<? super Throwable> errorConsumer,10 Runnable completeConsumer); 11
12Disposable subscribe(Consumer<? super T> consumer,13 Consumer<? super Throwable> errorConsumer,14 Runnable completeConsumer,15 Consumer<? super Subscription> subscriptionConsumer);subscribe可以一个参数都没有,也可以多达4个参数。
看下没有参数的情况:
xxxxxxxxxx31Flux<Integer> numbersFromFiveToSeven = Flux.range(5, 3);2
3numbersFromFiveToSeven.subscribe();注意,没有参数并不表示Flux的对象不被消费,只是不可见而已。
看下带参数的情况:consumer用来处理on each事件,errorConsumer用来处理on error事件,completeConsumer用来处理on complete事件,subscriptionConsumer用来处理on subscribe事件。
前面的3个参数很好理解,我们来举个例子:
xxxxxxxxxx51Flux<Integer> ints3 = Flux.range(1, 4);2 ints3.subscribe(System.out::println,3 error -> System.err.println("Error " + error),4 () -> System.out.println("Done"),5 sub -> sub.request(2));我们构建了从1到4的四个整数的Flux,on each就是打印出来,如果中间有错误的话,就输出Error,全部完成就输出Done。
那么最后一个subscriptionConsumer是做什么用的呢?
subscriptionConsumer accept的是一个Subscription对象,我们看下Subscription的定义:
xxxxxxxxxx51public interface Subscription {2
3 public void request(long n);4 public void cancel();5}Subscription 定义了两个方法,用来做初始化用的,我们可以调用request(n)来决定这次subscribe获取元素的最大数目。
比如上面我们的例子中,虽然构建了4个整数,但是最终输出的只有2个。
上面所有的subscribe方法,都会返回一个Disposable对象,我们可以通过Disposable对象的dispose()方法,来取消这个subscribe。
Disposable只定义了两个方法:
xxxxxxxxxx71public interface Disposable {2
3 void dispose();4
5 default boolean isDisposed() {6 return false;7 }dispose的原理是向Flux 或者 Mono发出一个停止产生新对象的信号,但是并不能保证对象产生马上停止。
有了Disposable,当然要介绍它的工具类Disposables。
Disposables.swap() 可以创建一个Disposable,用来替换或者取消一个现有的Disposable。
Disposables.composite(…)可以将多个Disposable合并起来,在后面统一做处理。
flux其他方法详见源码
Spring webflux入门实践
了解一步Servlet
在 Servlet3.0 之前,Servlet 采用 Thread-Per-Request 的方式处理 Http 请求,即每一次请求都是由某一个线程从头到尾负责处理。
如果一个请求需要进行 IO 操作,比如访问数据库、调用第三方服务接口等,那么其所对应的线程将同步地等待 IO 操作完成, 而 IO 操作是非常慢的,所以此时的线程并不能及时地释放回线程池以供后续使用,如果并发量很大的话,那肯定会造性能问题。
传统的 MVC 框架如 SpringMVC 也无法摆脱 Servlet 的桎梏,原因很简单,他们都是基于 Servlet 来实现的。如 SpringMVC 中大家所熟知的 DispatcherServlet。为了解决这一问题,Servlet3.0 中引入了异步 Servlet,然后在 Servlet3.1 中又引入了非阻塞 IO 来进一步增强异步处理的性能。
基本玩法
先来看一个大家熟悉的同步 Servlet:
xxxxxxxxxx231(urlPatterns = "/sync")2public class SyncServlet extends HttpServlet {3 4 protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {5 doGet(request, response);6 }7
8 9 protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {10 long start = System.currentTimeMillis();11 printLog(request, response);12 System.out.println("总耗时:" + (System.currentTimeMillis() - start));13 }14
15 private void printLog(HttpServletRequest request, HttpServletResponse response) throws IOException {16 try {17 Thread.sleep(3000);18 } catch (InterruptedException e) {19 e.printStackTrace();20 }21 response.getWriter().write("ok");22 }23}前端请求到达后,我们调用 printLog 方法做一些处理,同时把 doGet 方法执行耗时打印出来。
在 printLog 中,我们先休息 3s,然后给前端返回一个字符串给前端。
前端发送请求,最终 doGet 方法中耗时 3001 毫秒。
这是我们大家熟知的同步 Servlet。在整个请求处理过程中,请求会一直占用 Servlet 线程,直到一个请求处理完毕这个线程才会被释放。
接下来我们对其稍微进行改造,使之变为一个异步 Servlet。
有人可能会说,异步有何难?直接把 printLog 方法扔到子线程里边去执行不就行了?但是这样会有另外一个问题,子线程里边没有办法通过 HttpServletResponse 直接返回数据,所以我们一定需要 Servlet 的异步支持,有了异步支持,才可以在子线程中返回数据。
我们来看改造后的代码:
xxxxxxxxxx251(urlPatterns = "/async",asyncSupported = true)2public class AsyncServlet extends HttpServlet {3 4 protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {5 doGet(request, response);6 }7
8 9 protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {10 long start = System.currentTimeMillis();11 AsyncContext asyncContext = request.startAsync();12 CompletableFuture.runAsync(() -> printLog(asyncContext,asyncContext.getRequest(),asyncContext.getResponse()));13 System.out.println("总耗时:" + (System.currentTimeMillis() - start));14 }15
16 private void printLog(AsyncContext asyncContext, ServletRequest request, ServletResponse response){17 try {18 Thread.sleep(3000);19 response.getWriter().write("ok");20 asyncContext.complete();21 } catch (InterruptedException | IOException e) {22 e.printStackTrace();23 }24 }25}这里的改造主要有如下几方面:
- @WebServlet 注解上添加 asyncSupported 属性,开启异步支持。
- 调用 request.startAsync(); 方法开启异步上下文。
- 通过 JDK8 中的 CompletableFuture.runAsync 方法来启动一个子线程(当然也可以自己 new 一个子线程)。
- 调用 printLog 方法时的 request 和 response 重新构造,直接从 asyncContext 中获取,注意,这点是【关键】。
- 在 printLog 方法中,方法执行完成后,调用 asyncContext.complete() 方法通知异步上下文请求处理完毕。
经过上面的改造之后,现在的控制台打印出来的总耗时几乎可以忽略不计了。
也就是说,有了异步 Servlet 之后,后台 Servlet 的线程会被及时释放,释放之后又可以去接收新的请求,进而提高应用的并发能力。
第一次接触异步 Servlet 的小伙伴可能会有一个误解,以为用了异步 Servlet 后,前端的响应就会加快。这个怎么说呢?后台的并发能力提高了,前端的响应速度自然会提高,但是我们一两个简单的请求是很难看出这种提高的。
Spring webflux是什么
Spring Boot Webflux 就是基于 Reactor 实现的。Spring Boot 2.0 包括一个新的 spring-webflux 模块。该模块包含对响应式 HTTP 和 WebSocket 客户端的支持,以及对 REST,HTML 和 WebSocket 交互等程序的支持。一般来说,Spring MVC 用于同步处理,Spring Webflux 用于异步处理。我们在Springboot 官网可以看到对WebFlux的介绍:

WebFlux 支持的容器有 Tomcat、Jetty(Non-Blocking IO API) ,也可以像 Netty 和 Undertow 的本身就支持异步容器。在容器中 Spring WebFlux 会将输入流适配成 Mono 或者 Flux 格式进行统一处理。另外在上层服务端支持两种不同的编程模型: - 基于 Spring MVC 注解 @Controller 等 - 基于 Functional 函数式路由
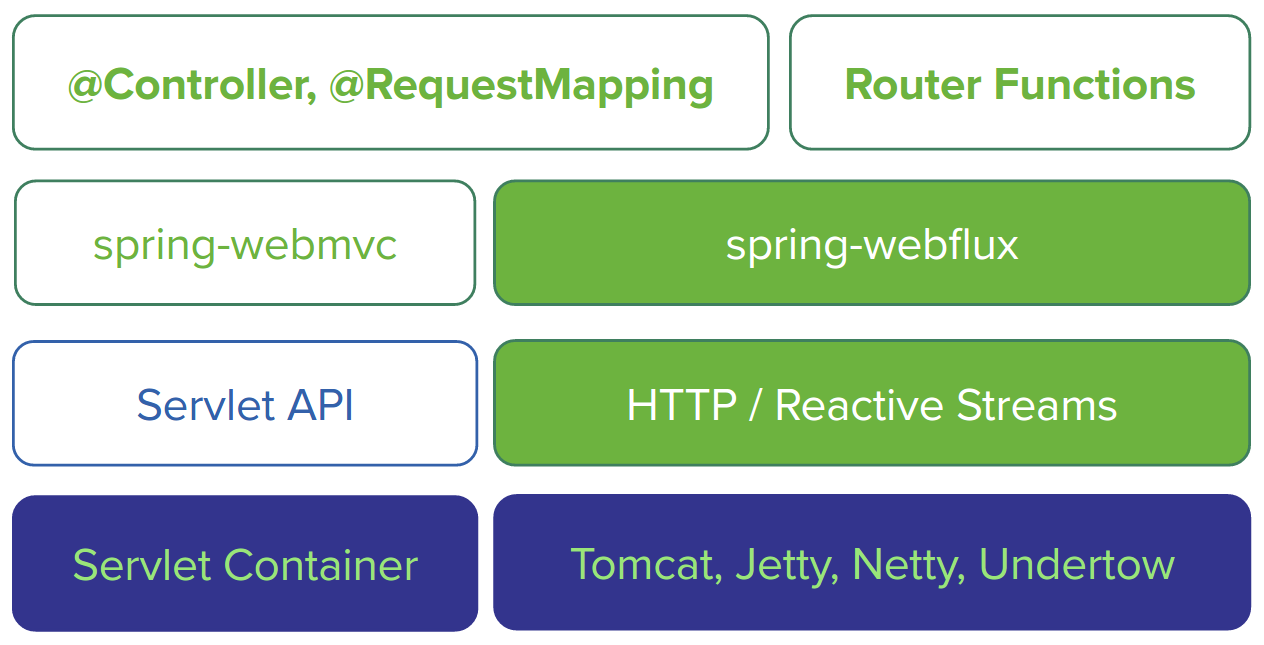
Spring webmvc 与Spring webflux对比

一图就很明确了,WebFlux 和 MVC 有交集,方便大家迁移。但是注意:
MVC 能满足场景的,就不需要更改为 WebFlux。因为命令式编程是编写、理解和调试代码的最简单方法。因为老项目的类库与代码都是基于阻塞式的。
如果你的团队打算使用非阻塞式web框架,WebFlux确实是一个可考虑的技术路线,而且它支持类似于SpringMvc的Annotation的方式实现编程模式,也可以在微服务架构中让WebMvc与WebFlux共用Controller,切换使用的成本相当小
在SpringMVC项目里如果需要调用远程服务的话,你不妨考虑一下使用WebClient,而且方法的返回值可以考虑使用Reactive Type类型的,当每个调用的延迟时间越长,或者调用之间的相互依赖程度越高,其好处就越大
微服务体系结构,WebFlux 和 MVC 可以混合使用。尤其开发 IO 密集型服务的时候,选择 WebFlux 去实现。WebFlux能解决IO多路复用
WebFlux对比WebMvc并发模型
SpringMVC基于的Servlet并发模型
servlet由servlet container进行生命周期管理。container启动时构造servlet对象并调用servlet init()进行初始化;container关闭时调用servlet destory()销毁servlet;container运行时接受请求,并为每个请求分配一个线程(一般从线程池中获取空闲线程)然后调用service()。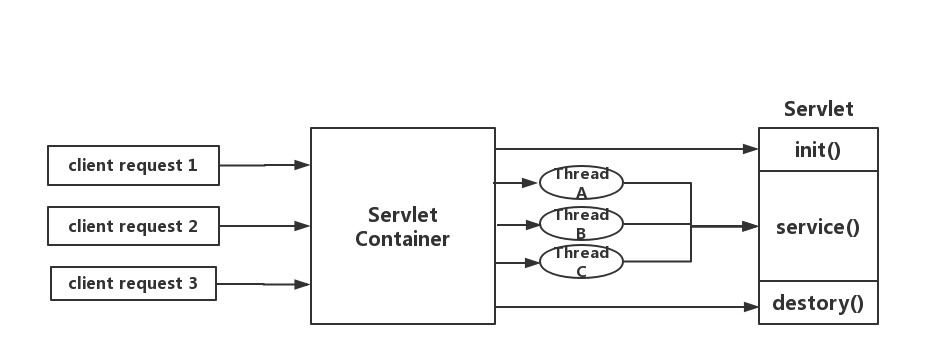
处理请求的时候同步操作,一个请求对应一个线程来处理,并发上升,线程数量就会上涨(上线文切换,内存消耗大)影响请求的处理时间。现代系统多数都是IO密集的,同步处理让线程大部分时间都浪费在了IO等待上面。虽然Servlet3.0后提供了异步请求处理与非阻塞IO支持,但是使用它会远离Servlet API的其余部分,比如其规范是同步的(Filter, Servlet)或阻塞的(getParameter,getPart),而且其对响应的写入仍然是阻塞的。
WebFlux并发模型
WebFlux模型主要依赖响应式编程库Reactor,Reactor 有两种模型,Flux 和 Mono,提供了非阻塞、支持回压机制的异步流处理能力。WebFlux API接收普通Publisher作为输入,在内部使其适配Reactor类型,使用它并返回Flux或Mono作为输出。
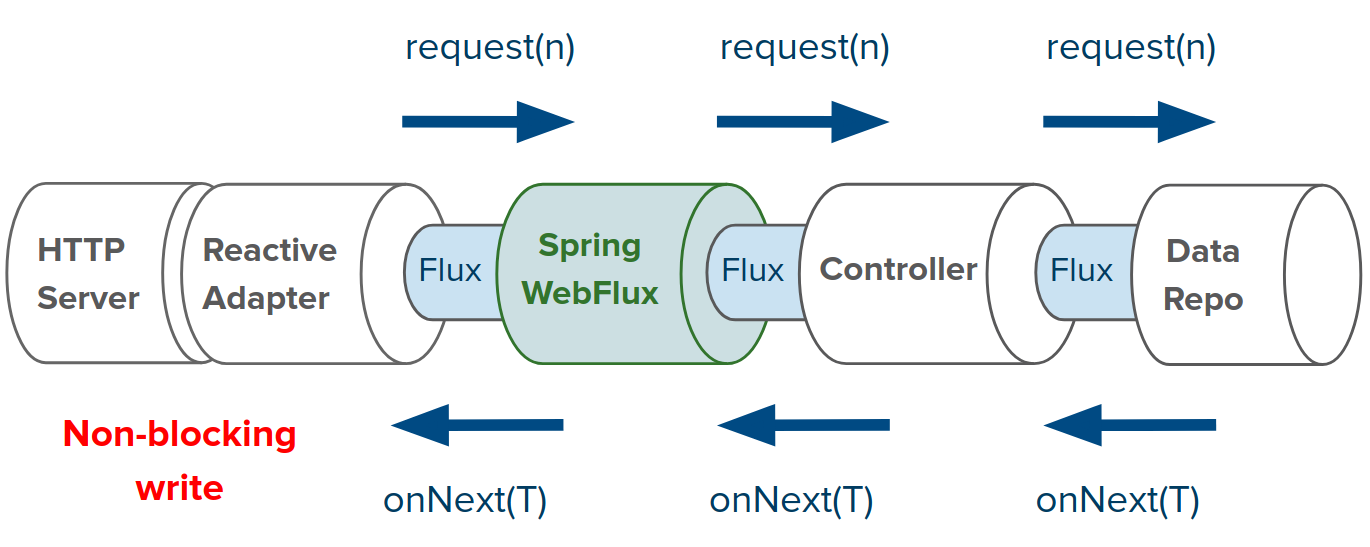
WebFlux 使用Netty作为默认的web服务器,其依赖于非阻塞IO,并且每次写入都不需要额外的线程进行支持。
也可以使用Tomcat、Jetty容器,不同与SpringMVC依赖于Servlet阻塞IO,并允许应用程序在需要时直接使用Servlet API,WebFlux依赖于Servlet 3.1非阻塞IO。使用Undertow作为服务器时,WebFlux直接使用Undertow API而不使用Servlet API。
当WebFlux运行在Netty服务器上,其线程模型如下:
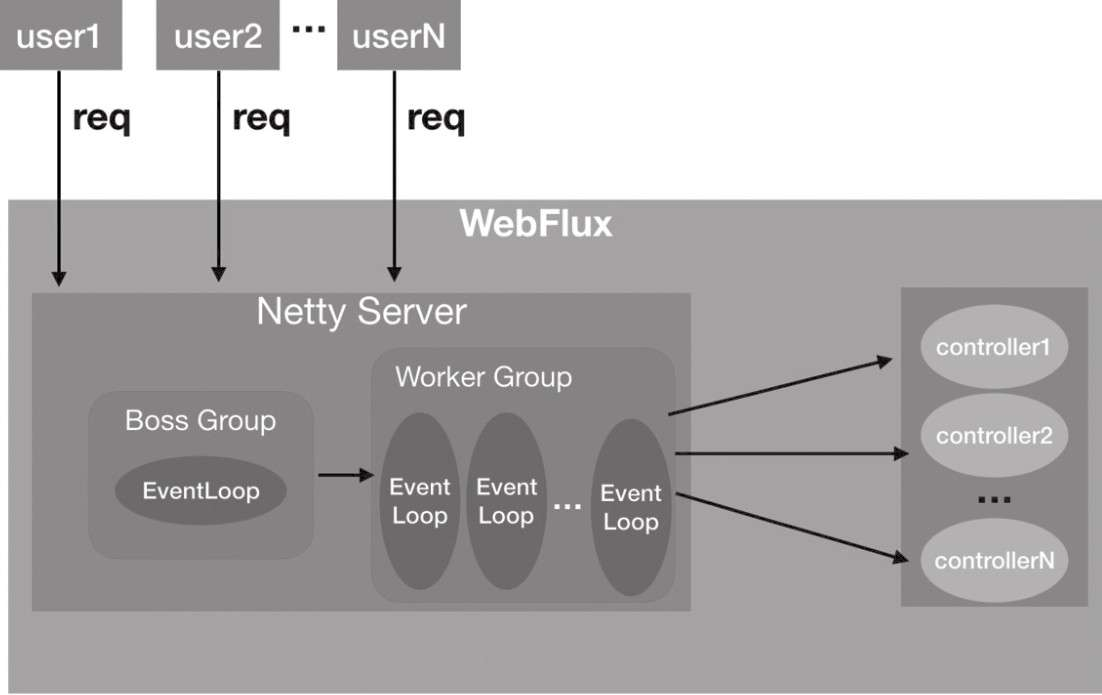
NettyServer的Boss Group线程池内的事件循环会接收这个请求,然后把完成TCP三次握手的连接channel交给Worker Group中的某一个事件循环线程来进行处理(该事件处理线程会调用对应的controller进行处理)。所以WebFlux的handler执行是使用Netty的IO线程进行执行的,所以需要注意如果handler的执行比较耗时,会把IO线程耗尽导致不能再处理其他请求,可以通过Reactor的publishOn操作符切换到其他线程池中执行。
Spring webfulx的crud实践
添加 webflux 依赖
xxxxxxxxxx41<dependency>2 <groupId>org.springframework.boot</groupId>3 <artifactId>spring-boot-starter-webflux</artifactId>4</dependency>定义接口
新建一个 controller 包,用来放置对外的接口类,再创建一个 HelloWebFluxController.class 类,定义两个接口:
xxxxxxxxxx271package com.tencent.spring.webflux.demo.controller;2
3import com.tencent.spring.webflux.demo.bean.User;4import org.springframework.web.bind.annotation.GetMapping;5import org.springframework.web.bind.annotation.RestController;6import reactor.core.publisher.Mono;7
8/**9 * @author joelzzhang10 */11public class HelloWorldWebFluxController {13
14 ("/hello")15 public String hello() {16 return "Hello, WebFlux !";17 }18
19 ("/user")20 public Mono<User> getUser() {21 User user = new User();22 user.setName("user");23 user.setDesc("user");24 return Mono.just(user);25 }26}27
User.java:
xxxxxxxxxx191package com.tencent.spring.webflux.demo.bean;2
3import lombok.Data;4
5/**6 * @author joelzzhang7 */8public class User {10 /**11 * 姓名12 */13 private String name;14 /**15 * 描述16 */17 private String desc;18}19
以上控制器类中,我们使用的全都是 Spring MVC 的注解,分别定义了两个接口:
- 一个 GET 请求的
/hello接口,返回Hello, WebFlux !字符串。 - 又定义了一个 GET 请求的
/user方法,返回的是 JSON 格式User对象。
这里注意,User 对象是通过 Mono 对象包装的,你可能会问,为啥不直接返回呢?
在 WebFlux 中,Mono 是非阻塞的写法,只有这样,你才能发挥 WebFlux 非阻塞 + 异步的特性。
测试接口
启动项目,查看控制台输出:
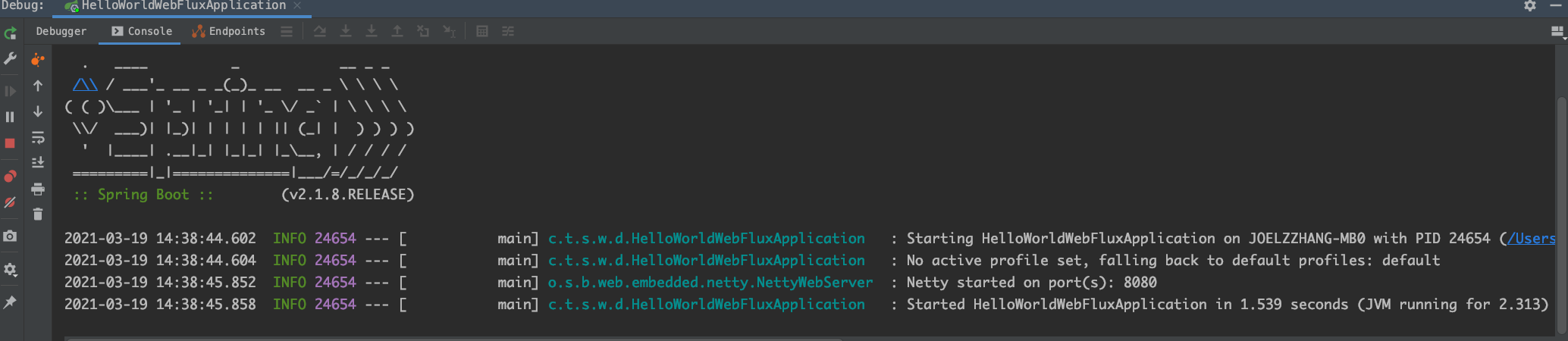
当控制台中输出中包含 Netty started on port(s): 8080 语句时,说明默认使用 Netty 服务已经启动了。
打开浏览器,先对 /hello 接口发起调用:
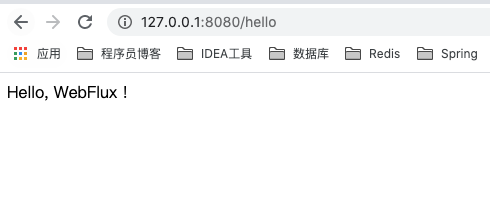
返回成功。
再来对 /user 接口测试一下:
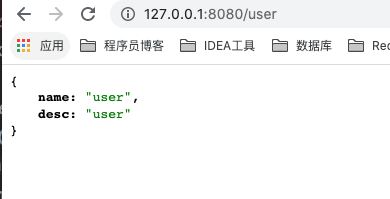
返回 JSON 格式的 User 实体也是 OK 的!
Crud操作见代码解读
基于 Functional 函数式路由实现 RESTful API
创建一个 Route 类来定义 RESTful HTTP 路由
xxxxxxxxxx311package com.tencent.spring.webflux.demo.config;2
3import static org.springframework.web.reactive.function.server.RequestPredicates.GET;4import static org.springframework.web.reactive.function.server.RouterFunctions.route;5import static org.springframework.web.reactive.function.server.ServerResponse.ok;6
7import com.tencent.spring.webflux.demo.bean.City;8import com.tencent.spring.webflux.demo.service.CityHandler;9import org.springframework.context.annotation.Bean;10import org.springframework.context.annotation.Configuration;11import org.springframework.web.reactive.function.server.RouterFunction;12
13/**14 * @author joelzzhang15 */16public class Routes {18
19 private CityHandler cityService;20
21 public Routes(CityHandler cityService) {22 this.cityService = cityService;23 }24
25 26 public RouterFunction<?> routerFunction() {27 return route(GET("/api/city/{id}"),28 req -> ok().body(29 cityService.findCityById(1L), City.class));30 }31}
Spring webflux为啥不能操作mysql
Spring Boot 2.0 这里有两条不同的线分别是:
- Spring Web MVC -> Spring Data
- Spring WebFlux -> Spring Data Reactive
所以这里问题的答案是,如果使用 Spring Data Reactive ,原来的 Spring 针对 Spring Data (JDBC等)的事务管理肯定不起作用了。因为原来的 Spring 事务管理(Spring Data JPA)都是基于 ThreadLocal 传递事务的,其本质是基于 阻塞 IO 模型,不是异步的。但 Reactive 是要求异步的,不同线程里面 ThreadLocal 肯定取不到值了。自然,我们得想想如何在使用 Reactive 编程是做到事务,有一种方式是 回调 方式,一直传递 conn : newTransaction(conn ->{})
因为每次操作数据库也是异步的,所以 connection 在 Reactive 编程中无法靠 ThreadLocal 传递了,只能放在参数上面传递。虽然会有一定的代码侵入行。进一步,也可以 kotlin 协程,去做到透明的事务管理,即把 conn 放到 协程的局部变量中去。 那 Spring Data Reactive Repositories 不支持 MySQL,进一步也不支持 MySQL 事务,怎么办?
答案是,这个问题其实和第一个问题也相关。 为啥不支持 MySQL,即 JDBC 不支持。大家可以看到 JDBC 是所属 Spring Data 的。所以可以等待 Spring Data Reactive Repositories 升级 IO 模型,去支持 MySQL。也可以和上面也讲到了,如何使用 Reactive 编程支持事务。
R2DBC简介
Spring data R2DBC是更大的Spring data 系列的一部分,它使得实现基于R2DBC的存储库变得容易。R2DBC代表反应式关系数据库连接,这是一种使用反应式驱动程序集成SQL数据库的规范。Spring Data R2DBC使用属性的Spring抽象和Repository支持应用于R2DBC。它使得在反应式应用程序堆栈中使用关系数据访问技术构建Spring驱动的应用程序变得更加容易。
Spring Data R2DBC的目标是在概念上变得简单。为了实现这一点,它不提供缓存、延迟加载、写后处理或ORM框架的许多其他特性。这使得Spring Data R2DBC成为一个简单、有限、固执己见的对象映射器。
Spring Data R2DBC允许一种 functional 方法与数据库交互,提供R2dbcEntityTemplate作为应用程序的入口点。
首先选择数据库驱动程序并创建R2dbcEntityTemplate实例:
- H2 (io.r2dbc:r2dbc-h2)
- MariaDB (org.mariadb:r2dbc-mariadb)
- Microsoft SQL Server (io.r2dbc:r2dbc-mssql)
- MySQL (dev.miku:r2dbc-mysql)
- jasync-sql MySQL (com.github.jasync-sql:jasync-r2dbc-mysql)
- Postgres (io.r2dbc:r2dbc-postgresql)
- Oracle (com.oracle.database.r2dbc:oracle-r2dbc)
下次分享解释
Spring cloud gateway
下次分享
参考资料
《Reactive programming 一种技术各自表述》